1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| # coding:utf-8
import aiohttp
import asyncio
from bs4 import BeautifulSoup
from bs4 import SoupStrainer
import json
import csv
import os
import time
import sys
# Linux下使用uvloop代替自带的loop
if sys.platform == 'linux':
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
# winddows下使用IOCP
if sys.platform == 'win32':
loop = asyncio.ProactorEventLoop()
asyncio.set_event_loop(loop)
async def getWeb(slug, sem):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
url = 'https://coinmarketcap.com/currencies/{}/'.format(slug)
try:
with await sem:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers, timeout=10) as resp:
return await resp.text()
except Exception as e:
print(e)
# 先抓取列表
async def getList():
global result
url = 'https://files.coinmarketcap.com/generated/search/quick_search.json'
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
async def main(slug, sem):
global link
# 因为数量不是很大,这里直接用字典来缓存结果
# 数量多的话可以使用redis来做缓存
link = {}
try:
html = await getWeb(slug, sem)
# 使用beautifulsoup解析文档
only_a_title = SoupStrainer('ul', attrs={'class': 'list-unstyled'})
soup = BeautifulSoup(html, "lxml", parse_only=only_a_title)
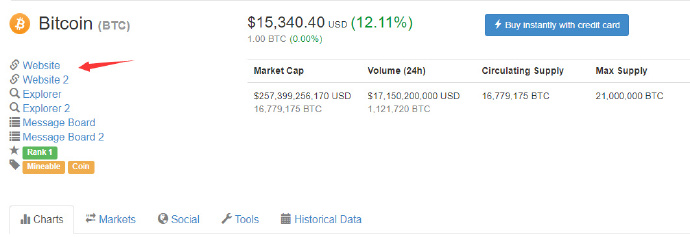
links = soup.select('span[title="Website"] ~ a')
r = []
if links is not None:
for x in links:
r.append(x['href'])
link[slug] = ','.join(r)
print(r)
except Exception as e:
print(e)
try:
start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(getList())
# 控制并发数
sem = asyncio.Semaphore(200)
tasks = [main(x['slug'], sem) for x in json.loads(result)]
loop.run_until_complete(asyncio.wait(tasks))
except Exception as e:
print(e)
path = os.path.join(os.path.split(os.path.realpath(__file__))[0], 'coin.csv')
# 把抓取结果写到csv文件里面
with open(path, 'w') as f:
fieldnames = ['rank', 'name', 'symbol', 'website']
wr = csv.DictWriter(f, fieldnames=fieldnames)
wr.writeheader()
for x in json.loads(result):
print(x['rank'], x['name'])
s = x['slug']
if s in link:
site = link[s]
else:
site = ''
wr.writerow({'name': x['name'], 'symbol': x['symbol'], 'rank': x['rank'], 'website': site})
print(time.time() - start)
|